
Scalable Video Coding Takes Center Stage at CWC Research Review
San Diego, CA, December 13, 2006 -- During a live video conference, people with wildly different technical constraints are all watching the best possible version of your video even though you’re only providing one video stream. This ability to serve up just one video stream for many different users requires “scalable video coding” – one of the hot topics in wireless communications discussed at a UCSD Center for Wireless Communications (CWC) research review in November.
|

Cosman and other UCSD electrical engineers and CWC-affiliated researchers provided industry partners, UCSD faculty and students with updates on CWC’s research projects at the Fall 2006 Research Review.
While much of this article will focus on scalable video coding, faculty members who spoke at the review also presented research on Coding for Wireless Networks, MIMO Wireless Communication Systems, Bandwidth Efficient Communications and Active Wireless Spaces.
In the session on Coding for Wireless Networks, Alon Orlitsky described his work with coauthors on using silence to preserve energy in sensor networks. Using pulses and silences instead of 1s and 0s to convey information can reduce the amount of communication required, which, in turn, reduces bandwidth needs. This approach could potentially be used in several applications such as sensors that detect motion or other activity. “If you can find a way to be silent most of the time, you can save a lot of energy,” said Orlitsky who holds joint appointments in the Electrical and Computer Engineering and the Computer Science and Engineering Departments of the Jacobs School, and is also the director of the Information Theory and Applications (ITA) Center, established in 2006 by Calit2.
At the research review, Bhaskar Rao, a professor of electrical and computer engineering at the Jacobs School led a tutorial on MIMO Wireless Communication while Truong Nguyen, also a professor in the electrical and computer engineering department provided an introduction to video compression algorithms and scalable video coding. Some of the basics of scalable video coding, as well as a taste of Cosman’s recent research, are described below.
Scalable Video Coding
The big idea in scalable video coding is that you can provide one compressed video stream and any user can pull out just what is needed to get the best quality video based on technical constraints. Rather than a “one size fits all” approach, scalable video coding follows a “take what you need and ignore the rest” strategy.
Video can be coded so that it is scalable in different ways: it can be spatially scalable and accommodate a range of resolutions on users’ viewing screens; it can be temporally scalable and offer different frame rates; it can be scalable in terms of quality – or SNR (signal-to-noise ratio) – and offer video at different quality levels to accommodate differences in bitrates in the transmission channel. The capacity of transmission channels determines, in large part, the quality of each frame of the video.
At the Research Review, Cosman focused on SNR or quality scalable video coding. To understand how SNR scalable video coding works, you first need to understand, in general terms, how a video signal gets from one device, across a network – perhaps wireless – to a second viewing device such as a laptop or a PDA.
The original video is fed into an “encoder” that generates a compressed version of the video that is available to eligible viewers. This compressed bitstream travels to its destination via a transmission channel (such as the Internet or a wireless channel). The compressed bitstream that arrives at the destination must then be reconstructed back into video. The “decoder” performs the task of reconstruction.
|
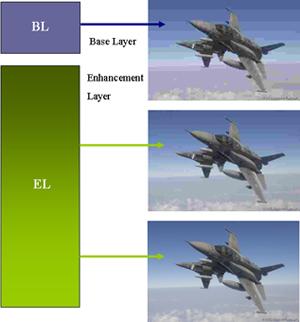
Sending Video, Sending Instructions
When an original video is encoded and travels to a viewer, you are sending some information about each frame, plus a detailed set of instructions that specifies how information can be shared between frames when there are redundancies – when the same objects appear in multiple frames. If a house that appears in one frame reappears in the next ten frames, you don’t need to send the full picture of the house again and again. Instead, you send the house region of the image once and then specify how the house in the following frames differs from the first house region you sent.
To refer back to past frames, you need to cut up the current frame being encoded into a series of blocks. You then look for identical or nearly identical blocks in different frames, and reuse this information instead of sending it multiple times.
|
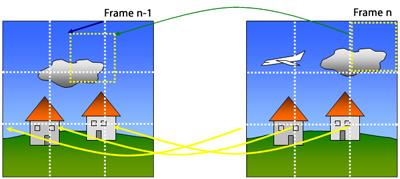
While reconstructing this same frame, you may find a block that is lined up perfectly with respect to the reference frame but darker. In this case, you would send the motion vector (0,0) and a little information that says “shade it a little darker.” This extra information is called residual information.
Still in this same frame, if a cloud has moved and changed shape with respect to the reference frame, the boxes in the reference frame that best match the boxes in the frame you are reconstructing will not be in the same spot. In this case, the encoder generates a motion vector to represent the spatial offset and a substantial residual that says something like, “erase these cloud pixels and make them sky pixels.”
Videos Drifting Apart
“This whole thing works beautifully,” said Cosman, “if the compressed version of the video that the decoder receives and uses to reconstruct the video is nearly identical to what the encoder sent.”
Unfortunately, the compressed version of the video sent by the encoder is often cut off before it reaches the decoder of the person who wants to watch the video. When the encoder and decoder are not working from the same version of the video, errors caused by “drift” start to accumulate.
Drift can be especially acute in wireless applications, where fluctuations in bandwidth can knock out much of the information that the encoder tries to send to the decoder. If the decoder does not have what the encoder sent, then the decoder will not be able to faithfully reconstruct the frame. For example, if the encoder tells the decoder to take the pixels from frame 10 that form the shadow along a specific part of the house and make them darker in frame 11, but the decoder and encoder have different versions of frame 10, then the reconstructed version of frame 11 is not going to be right. The two versions of the video will continue drifting apart, frame by frame, as errors propagate through the video.
One drastic strategy for avoiding drift is to have the encoder refer back to just base layers of frames.
“Base layers do not contain high quality versions of images, but you can often assume that they will get through the transmission channel. If you always refer back to just the base layer, you know the encoder and decoder are talking about the same thing and there will be no drift. But, the quality of the video won’t be very good. High quality versus reliable representation -- this is the dilemma” explained Cosman.
There is wiggle room, however, in this tradeoff between fighting drift and accepting low quality reconstructed video. In addition, while base layers may be all some wireless users can handle, users with higher capacity connections can take much more information per frame, and a SNR scalable system must accommodate both kinds of users, as well as everyone between.
In her Research Review presentation, Cosman focused on work she did with Athanasios Leontaris, a former student.
Instead of trying to avoid drift, you can fight it by cutting it off regularly by referring back to just the base layer at regular intervals, Cosman explained. For each frame that you send just the base layer, you ensure that the encoder and decoder will have the same information for that frame, thus cutting out any drift that may have accumulated since the last time you sent just a base layer. For the rest of the frames, you are sending more information with the aim of getting higher quality video – but with the knowledge that you may be incurring drift.
The international video compression standard Cosman works with for scalable video coding is called H.264.
“The thing about H.264 that a lot of people don’t understand is that it is extraordinarily flexible. It doesn’t tell you how to encode a particular video,” explained Cosman. Instead, H.264 sets guidelines for how to tell the encoder to compress a video into a bitstream and how to tell the decoder to decompress the bitstream and reconstruct the video.
“Researchers are spending lots of time figuring out clever ways to use the standard,” said Cosman, who is one of those researchers.
Cosman helped pioneer the idea of pulsing the quality of base layer frames to improve overall image quality. Through base layer frame pulsing, you send base layer frames that are higher quality than usual at regular intervals, or when you have a frame that may be especially important. “There is nothing in the standard that says you have to give equal bits to all frames. You can pulse the quality of base layer frames by choosing to give extra bits to every 10th frame or 20th frame, for example, or to a frame that has a new object in it,” explained Cosman.
With H.264, you can also refer back to more than just the previous frame in the video. You can refer back to a higher quality but temporally distant frames and use them as long term references that can boost the quality of the reconstructed video with just a minimal increase in the number of bits sent.
“The standard doesn’t say which frames to keep around as long term references; it just says you can do this. H.264 describes the syntax for telling the decoder which frame to use and how to encode the information of the motion vector. Different companies make proprietary encoders that are all compliant with the standard,” said Cosman.
If you’re watching live video and your bandwidth is fluctuating, you don’t know what is getting through to the decoder or where drift is occurring.
“There is a lot of interesting research to be done on how to make use of H.264 in clever ways. Our work is showing that if you assume that there is some amount of drift and you periodically cut it off, you’re going to do better than if you ignore the drift problem. Even if you are wildly far off in estimating the drift, you’re still better off by assuming there is some drift,” explained Cosman.
Related Links
Center for Wireless Communications
Pamela Cosman Website
Information Theory and Applications Center